
分布式锁、分布式自旋锁在金融支付系统中的应用(真实场景)
日期: 2021-04-15 分类: 个人收藏 1055次阅读
前言
分布式锁在当下微服务架构的系统中有着举足轻重的作用,特别是金融支付系统这些和钱相关强一致的系统被广泛的使用,下面我将介绍先真实的支付系统中如何利用分布式锁来实现一些特殊的需求。
1. 分布式锁
1.1 什么是分布式锁
想必做web开发的或多或少都会听过、或者用过,这里我就简单介绍下分布式锁的场景和实现方式,如果需要详细的实现可以稍微搜一下非常的多。
所谓分布式锁在我看来就是能让同一资源在不同机器、应用中保持互斥:
如果理解java中的锁机制,其实就是将java锁做成跨服务器,从而协调各个实例。
分布式锁实现方式有很多,如redis、zookeeper,选择主要看场景:
了解cap原则的同学应该知道 分布式系统 只能做到AP(可用性牺牲强一致)或者CP(强一致牺牲可用),这也对应了 redis和zookeeper 这两种分布式锁应用的场景,但是目前看来redis分布式锁的应用会广泛一些,因为现在系统很多都是异步的根本无法保证强一致性,而是最终一致性,而redis锁的效率也高于zookeeper,所以一般互联网公司实际场景应用会趋向于redis
分布式锁实现原理:
其实分布式锁的实现原理非常简单,这里来一个比喻: 就好比大家去占坑,发现已经有人了就走了以redis分布式锁为例,利用redis的SETNX 接口设置一个key,key存在就不能上锁,key不存在则返回能上锁
1.2 金融系统中的实践
如果做过订单相关的业务需求,应该会对订单号并不陌生,用来做订单唯一的标识,那么想象一下如果有一些支付的需求第三方的支付机构类似支付宝,会要求调用方上传唯一的订单号,而调用方的行为第三方支付系统是无法控制的,如果你是支付宝的开发者,调用方同一个订单号同时重复请求支付宝,不做任何的防御会出现什么问题?
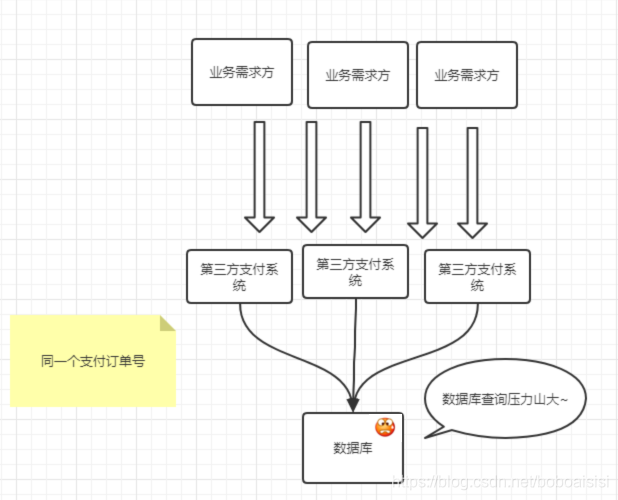
1.由于会校验订单号是否存在,每次都会去查询数据库导致数据库压力大
2.由于是并发的请求,两笔订单会分布到两台机器,可能会导致插入两笔同样的数据
那么如何用比较优雅解决上述的问题呢?
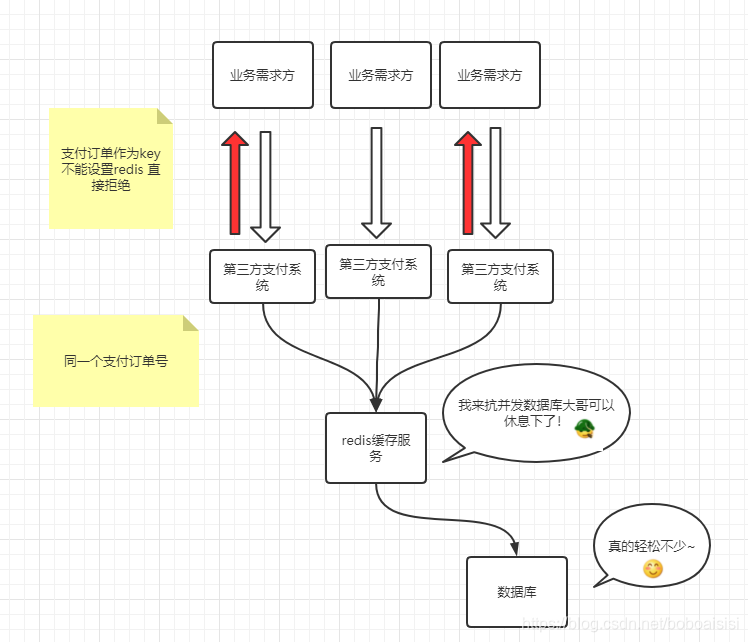
刚才的问题抽象一下大致分以下几点:
1.如何让同一时间的请求不每次查询数据库
2.在不同的机器上,如果是同一个请求是不是可以直接拦截掉不走后面下单逻辑
是时候分布式锁这时候就派上用场了!
做法非常简单:
1.利用第三方的订单号和商户的id作为key
2.锁定的时间可以设置为几秒,这样几秒内如果同一个订单号就会被拒绝保护后面查询数据库的资源
有同学会问,如果设置时间太短导致第一个请求还没结束,又一个同样订单号的请求过来怎么办?
其实问题不是很大,因为对于支付的下单接口,如果查询不到第三方订单号,会直接先把订单进行入库时间是很短的,一般锁5秒即可
2. 分布式自旋锁
2.1 什么是分布式锁自旋锁
分布式锁和分布式自旋锁从字面上就可以知道区别在于自旋,所谓自旋我还是以占坑的例子来解释下: 普通分布式锁就是发现坑被人占了,那我不等了直接走呗,而分布式自旋锁则是:坑被人占了,找别的太麻烦了,我就在坑位前等着,这里还衍生出一个概念就是“坑如果被释放,是大家按排队按顺序入坑呢,还是发现有坑位了大家蜂拥而上看谁有本事抢到”,这里就是一个公平锁和非公平锁的区别这里大致点一下,有兴趣的可以搜一下相关文章的实现方式。
分布式锁自旋实现原理:
分布式自旋锁的难点就是自旋等待这块,我们以redis为例,我们要考虑两个问题:
1.由于抢不到锁的都得等待抢到锁的释放锁才能再一次去抢占锁,那如果抢到锁的一直不释放会怎么样?
2.抢到锁的线程有没有可能会释放别的锁,会有什么后果?
上面两个就是自旋带来的问题, 1.会导致排队太多系统奔溃 2.会导致脏数据
基于以上问题我们设计了如下的方案:
1.加锁必须要有超时时间,如果获得不到锁的线程可以一直在while循环里取尝试拿锁,直到拿到锁,或者锁已经超时(redission的做法是维护一个守护线程去每隔一段时间去看获得锁的客户端是否释放了锁,如果没有释放则会延长加锁时间,这里要根据不同场景去选择)
2.锁的释放要记录上锁线程的唯一标识,在请求的时候生成一个客户端的唯一id作为value放入redis缓存键值对中,释放锁的时候去判断释放锁的客户端是否是加锁的客户端,从而避免被别的客户端释放的情况。
2.2 金融系统中的实践
1.部分退费场景
一般第三方支付都一笔支付订单都会支持多笔部分退费,这样就会有一个要求就是支付订单退款的金额是不能超过支付金额的
这里可以利用分布式锁对发起退款的逻辑进行锁定和排队,修改退款记录不会被多个客户端覆盖而产生脏数据。
1.所有子订单状态都为成功后修改主订单的状态
支付系统中会涉及到一笔主订单附带多笔子订单的业务,需要所有子订单都为成功后才能去把主订单修改成成功,而如果没有任何措施,在更新完子订单时候需要去查询所有子订单是否都为成功,这里会出现脏读,引入分布式锁则可以将处理做成串行化从而保护所有子订单的状态读取一定是正确的(当然也有别的方案如:引入一个分布式计数器,子单修改成功后加一,改完以后去查一下计数器数量是否等于子订单数量,然后去更新主订单)。
3.总结
本文是自己平时工作中遇到对分布式锁和分布式自旋锁的思考和应用,其实相关原理的文章很多但是很多局限于简单的例子并没有实际参考价值,希望本文对大家实际场景的引用有所帮助。
除特别声明,本站所有文章均为原创,如需转载请以超级链接形式注明出处:SmartCat's Blog
精华推荐